
Introduction
This summer, I had the chance to work as a full-time intern at Hyperledger. I am writing this post to share my experiences about working with Hyperledger and to report on the project itself and the impact it can have on the Hyperledger community as well as on my personal development.
My mentor was Salman Baset, an active member of the Hyperledger community. I must emphasize what a great mentor he was, always available, communicative and helpful. He gave me a lot of hints and helped me out when I got stuck, but, still, I had the freedom to make technical and strategic decisions. I have learned a lot from him, and he (and this project) provided a huge boost for my personal improvement.
The goal of the project
The main goal of the project was to create a mechanism to analyze and display ledger data from both operational and data-oriented aspects (e.g., allow selection of a particular key and visualization of updates to it).
What I accomplished
The main components of the project:
- An Elastic Beats agent (fabricbeat) written in Go that connects to peer(s), queries it, and ships its data to Elasticsearch and Kibana (core contribution of this project).
- Three different Fabric networks with chaincodes written in Go and Node.js (for testing).
- Applications for user enrollment and transaction submission using the node SDK (for generating test data).
- Elasticsearch cluster and Kibana server. (Docker Compose file is borrowed from an open source project.)
- Generic Kibana dashboards similar to Hyperledger Explorer, plus data-centric dashboards (contribution of this project).
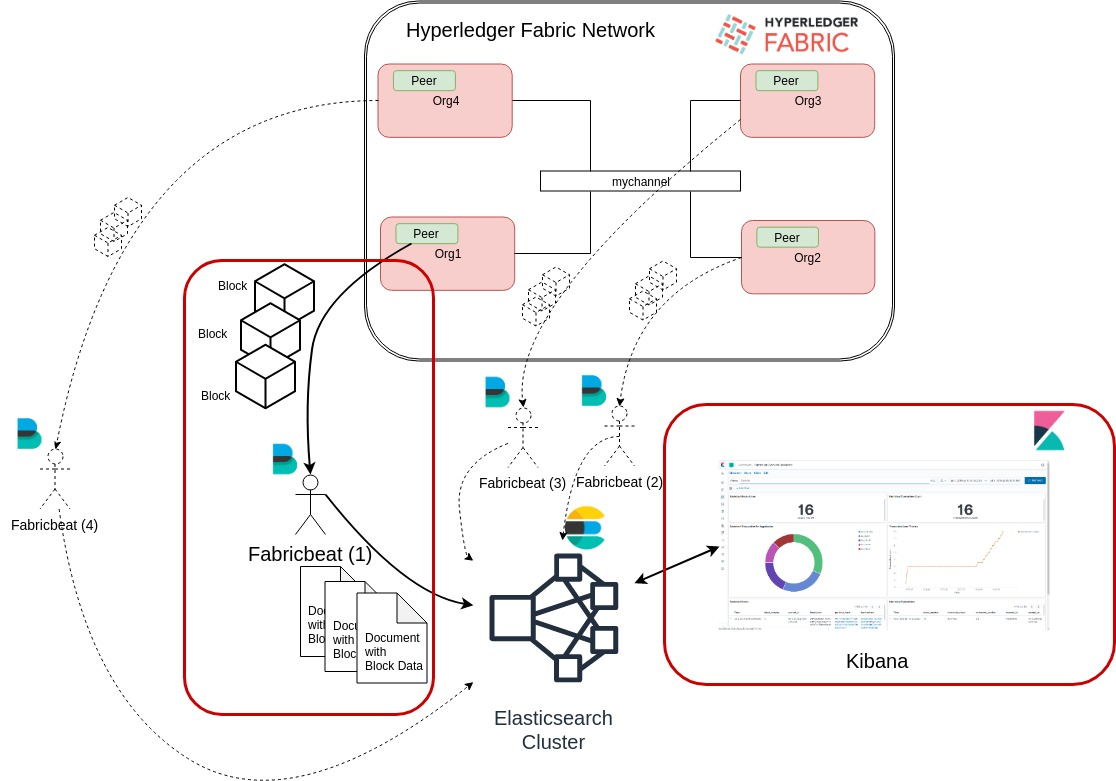
1. Architecture and basic data flow (the highlighted parts are the main contributions of this project)
The most exciting part of the project was learning a number of new technologies. I used Golang, Node.js, Elastic Beats, Elasticsearch, Kibana and, of course, Hyperledger Fabric. Designing the Beats agent and implementing the generic Kibana dashboards were great professional challenges, too, and it was an extraordinary experience to see them working.
I also created demo setups that can be installed and run with only one make command. They demonstrate the main features of the project.
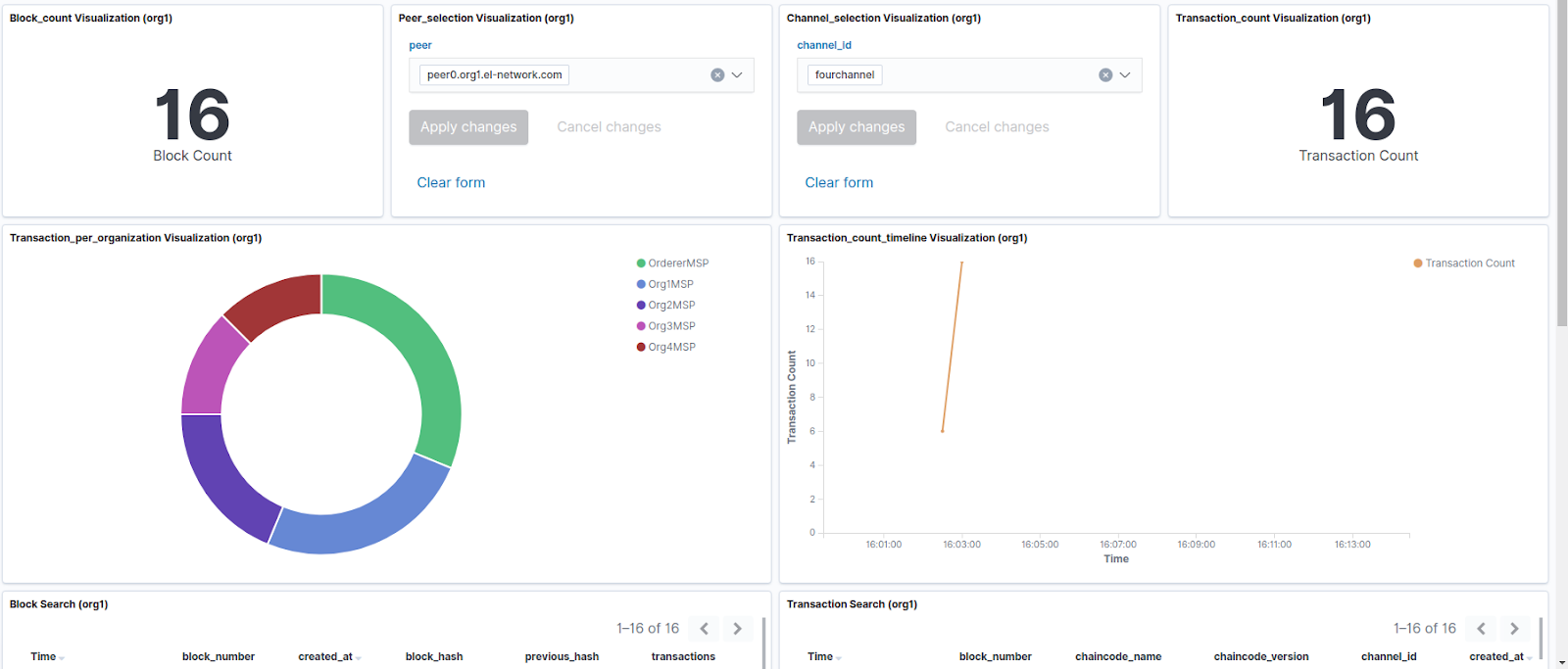
2. Operational dashboard (multiple fabricbeat agents can be run at the same time, we can select peer and channel from which we want to see the data)
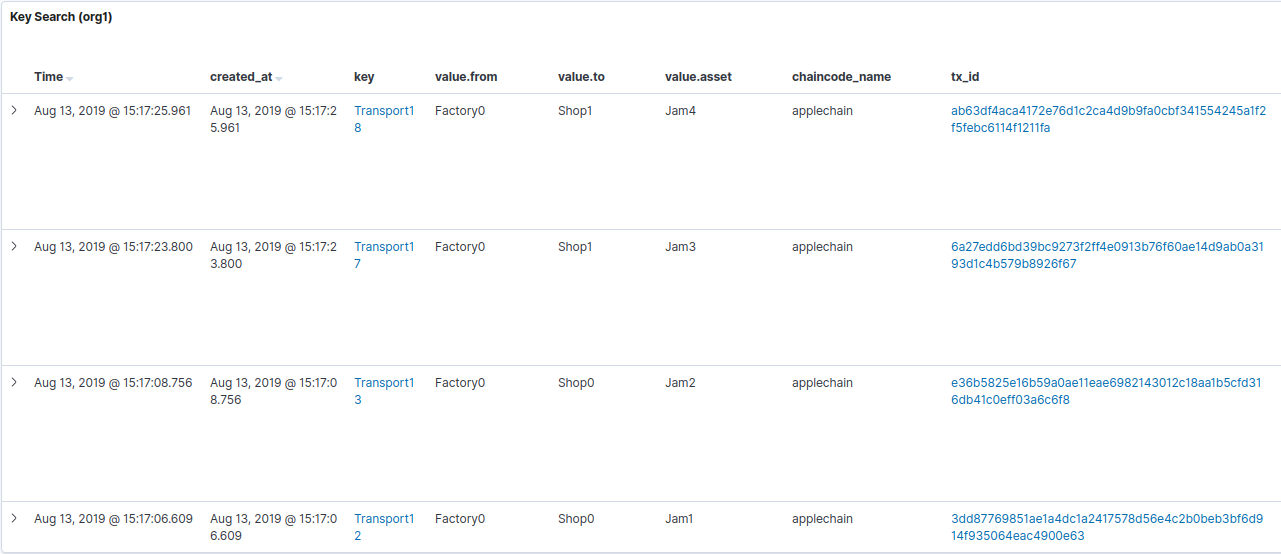
3. Searching for all the transports that departed from “Factory0”
Suggestions
Hyperledger Fabric uses an approach that wraps the data into multiple layers of meta data, and stores this whole package on the ledger. This makes analysis quite painful, since we have to do a lot of processing and unwrapping to obtain the most valuable parts of this data. Having the data indexed in a NoSQL database would make analysis much easier.
Plans for the future
This project has a lot of potential. A few ideas on how it could be improved and used in the future:
- The project provides a more customizable way for blockchain analysis than Hyperledger Explorer, with extended functionalities and data-centric analysis possibilities.
- Hyperledger Fabric writes ledger data to a file by default. By replacing the ledger file with
- Elasticsearch, MongoDB, CouchDB, or other appropriate database, the need for a separate Beats agent can potentially be eliminated. Further, having ledger data directly stored in a database (instead of a file) can potentially simplify Hyperledger Fabric deployment architecture in Production (e.g., by removing a separate instance of CouchDB per peer).
- This project could be generalized to work with every kind of blockchain implementation, not only Hyperledger Fabric.
We submitted the project to Hyperledger Lab, so further development is open for contribution. I am really excited to be a member of and work with the open source community!
For more details, please see my complete project report here.